defgetLineOfPage(page): url = r'https://www.luogu.com.cn/record/list?user=xxx&page='+str(page)#user=... text = getHTMLText(url,cookie) text = decode(text) #print(text) m = re.findall(r'"id":(.+?),', text) n = re.findall(r'"pid":(.+?),',text) ret = 0
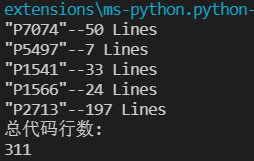
pointer = 0 for pointer inrange(len(n)): if n[pointer] in vis: continue eachUrl = r'https://www.luogu.com.cn/record/'+m[pointer] vis.append(n[pointer]) t = getLineOf(eachUrl) print("%s--%d Lines"%(n[pointer],t)) ret = ret+t return ret
defdecode(str): return ctx.call("decode",str) defgetHTMLText(url,cookie): try: response = requests.get(url, headers=header,cookies=cookie) return response.text except: return'' defgetLineOf(url): text = getHTMLText(url,cookie) return decode(text).count(r'\n') defgetLineOfPage(page): url = r'https://www.luogu.com.cn/record/list?user=...&page='+str(page)#改user text = getHTMLText(url,cookie) text = decode(text) #print(text) m = re.findall(r'"id":(.+?),', text) n = re.findall(r'"pid":(.+?),',text) ret = 0
pointer = 0 for pointer inrange(len(n)): if n[pointer] in vis: continue eachUrl = r'https://www.luogu.com.cn/record/'+m[pointer] vis.append(n[pointer]) t = getLineOf(eachUrl) print("%s--%d Lines"%(n[pointer],t)) ret = ret+t return ret url = ""
maxpage = 1#修改最大页数,去评测记录页看一下页数
now = 1 cnt = 0
while now <= maxpage: url = 'https://www.luogu.com.cn/record/list?user=...&page='+str(now)#修改 cnt = cnt+getLineOfPage(now) now = now+1